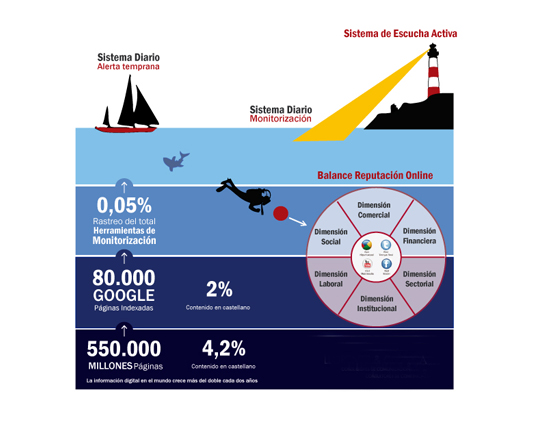
Años trabajando y seis decenas de empresas dedicadas a investigar la reputación de las compañías en internet, y resulta que están todas equivocadas. Y lo peor, grandes marcas lanzando y modificando productos merced a lo que les cuentan esos estudios. Pero haz esta cuenta y lo entenderás. La última estimación, de 2006, ya decía que en internet había 550.000 millones de webs; pero, por ejemplo, Facebook (con casi mil millones de usuarios) o Twitter (400 millones de mensajes al día) cuentan como una sola web. Porque los programas de rastreo usan a su vez Google, haciendo consultas automáticas, pero su robot no tiene “permiso” para entrar en la redes sociales.
Resumiendo: los buscadores solo rastrean el 15% de internet. Además, está el margen de error lingüístico: si estudiamos la reputación de Gas Natural, ¿cómo discrimina una máquina que no hablamos de un gas de tipo natural? Y más: ¿cómo saben que lo que se dice es bueno o malo? Después hay algunos filtros de corrección que dejan la muestra en casi nada. Y la agencia española de comunicación Llorente y Cuenca –que también investiga la reputación de las marcas para sus clientes– llegó a la conclusión de que se rastrea solo un 0,5% de la red, y de que el porcentaje de acierto de las herramientas que usa la industria es de ¡un 6%! Ínfimo.
Así que Adolfo Corujo, director senior de Comunicación Online de la agencia, está coordinando los trabajos de siete grupos de investigación de varias universidades europeas para mejorar esa “escucha” de la red. El proyecto, llamado LiMoSINe lo financia la UE y en él participan varios gurús europeos de la investigación online, como Ricardo Baeza-Yates, vicepresidente de Yahoo! de Investigación para Europa y Latinoamérica.
Por qué las mediciones no son buenas
El gran reto para conocer la reputación de una empresa consiste en que «cada vez que un usuario habla de una marca, esa marca se entere. Puede que haya 60 compañías de medición del prestigio. Muchas pymes españolas crean herramientas», comenta Corujo.
El directivo de Llorente y Cuenca cuenta las limitaciones de su herramientas, y cómo funcionan: «Consulta automática al buscador, almacenado de datos, luego filtrado (cita o no cita al cliente, características de la marca a las que alude, su nombre literal…). Pero hay que añadir una desambiguación para evitar confusiones (“gas natural”) y filtrar, qué vale y qué no. Y luego, la presentación de los datos, que incluye la valoración («polaridad», o sea, si son positivos o negativos) de esos datos estructurados.
Pero todos esos pasos están llenos de errores y eso acaba por dejar la fiablidad de los resultados porque puede ser que se esté trabajando sobre un 0,5% de las menciones reales que hay en la red. «Los resultados de búsqueda pueden aflorar de diferente modo en diferentes días, lugares… Hay herramientas que solo valen para un idioma, en un escenario determinado, sobre una cuestión concreta y en un período de tiempo limitado», comenta.
Quién está involucrado en LiMoSINe
El proyecto para mejorar el modo en que se bucea e investiga cuenta con la participación del Yahoo! Lab Research de la Universidad de Barcelona, y las universidades de Ámsterdam, de Trento y de Glasgow. Cada equipo se reparte una capa de información. Hay site equipos de investigación, 6 de los cuales son científicos. Despúes de econtrar el mejor modo de investigar la reputación online, harán herramientas para aplicar esos conocimientos. Cada equipo tiene que presentar un prototipo para analizar cada capa de información. Courujo y su agencia se ocupan de determinar las necesidades de las empresas y los criterios de calidad.
Pero la primera investigación, las que le llevó a la conclusión de que las herramientas actuales fallaban también es interesante. Se hicieron 106 equipos de investigación que tenían que crear un algoritmo que, usando 1000 tuits en inglés, tenían que analizar cuáles se referían a la empresa y cuáles no (simplemente si se referían o no, sin contar la polaridad). Se supone que la tecnología semántica en inglés se supone que es mejor. El equipo que mejor lo hizo acertó un 56%, o sea, la mitad de probabilidades…Eso lo reduce a un 6% porque el 50% es un algoritmo buleano, o sea, aleatorio.
Asombrosamente, hay empresas que dicen que logran un 86% de acierto en la polaridad, cuando la realidad es que solo se acierta un 6% simplemente al identificar al sujeto que se analiza.
Redacción QUO


